Project/한국어 대화 분류 및 요약
[Project] 한국어 대화 분류 및 요약 - 프로젝트 계획
gangee
2024. 5. 1. 18:29
728x90
반응형
프로젝트 계획
1. 프로젝트 필요성 및 의의
- 최근 몇 년간 자연어 처리를 활용한 AI 대화 서비스, 음성 제어 서비스의 수요가 늘고 있으며, 계속해서 발전되고 있음
- 자연어를 대상으로 하는 의도 분류는 많은 연구가 진행되고 있지만 일상 대화의 주제를 분류하는 연구는 많지 않음
- 대화 데이터를 주제별로 분류하였을 경우 어떤 주제에 어떤 대화가 이루어지는지 파악할 수 있음
- 현재, 생성형 AI는 방대한 양의 데이터를 학습하고 있어 특정 도메인을 지정하지 않으면 AI가 대화의 맥락을 이해할 때 어려움이 있을 수 있음
- 대표적인 현상 : Hallucination
Hallucination
- AI가 정보를 처리하는 과정에서 발생하는 오류
- 내재적 현상 : 맥락과 관련 없는 내용을 출력
- 외재적 현상 : 출처가 명확하지 않은 내용을 출력
2. 프로젝트 목적
- 한국어 대화 데이터를 활용하여 BERT 기반의 NLP 모델을 통해 대화 주제 분류 및 요약 시스템 구현
3. 프로젝트 목표
- 검색 및 크롤링을 통해 대화 텍스트 수집
- 한국어 특성을 고려하여 텍스트 데이터 전처리
- 언어 기반 모델을 통해 대화 주제 파악 및 요약
- 테스트를 통해 정확도 검증 및 성능 향상
4. 프로젝트 시 고려해야 할 점
- 한국어 특성을 반영한 별도의 분석이 필요함
- 한국어는 어간과 접사가 붙어 의미와 문법적 기능이 변화하는 교착어
- AI의 경우, 문법 규칙에 맞춰 분석하여야 정확한 결과를 도출할 수 있기에 전처리 과정이 중요할 것으로 예측하였음
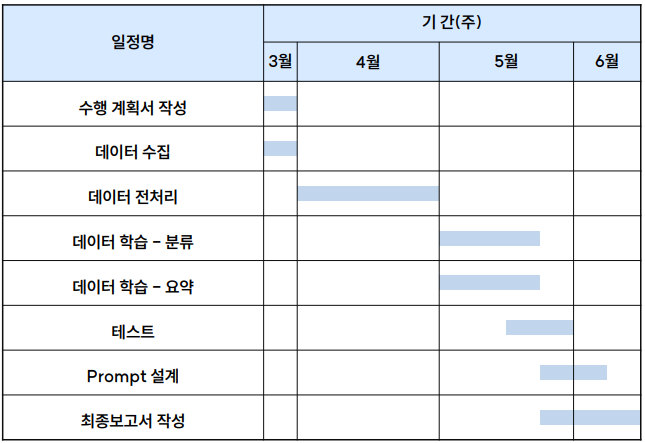
5. 프로젝트 과정 및 일정
728x90
반응형