Project/한국어 대화 분류 및 요약
[Project] 한국어 대화 분류 및 요약 - 모델 학습
gangee
2024. 6. 9. 22:05
728x90
반응형
BERT 모델 학습
- AI Hub데이터의 경우 라벨이 없는 데이터로 비지도학습 사용
- 대표적인 군집화 모델 K-means을 사용하여 파인튜닝 진행
모델 학습 과정
- pkl파일로 저장된 데이터를 학습할 수 있게 list 형태로 변환
# 'filtered_file.pkl'에서 데이터 로드
with open('filtered_file.pkl', 'rb') as f:
analyzed_data = pickle.load(f)
# list 형태로 변환
texts = list(analyzed_data.values())- 모델이 처리할 수 있게 텍스트 데이터를 숫자 벡터로 변환하는 텍스트 임베딩 추출 함수 정의
- 배치 단위로 텍스트를 처리하고 토큰화하여 입력 형식으로 변환
- 각 문장의 토큰 임베딩을 추출하고 numpy 배열로 변환
# 텍스트 임베딩 추출 함수 (배치 처리)
def get_embeddings(texts, tokenizer, model, batch_size=32):
embeddings = []
with torch.no_grad():
for i in tqdm(range(0, len(texts), batch_size)):
batch_texts = texts[i:i + batch_size]
inputs = tokenizer(batch_texts, return_tensors='pt', truncation=True, padding=True, max_length=128, add_special_tokens=True)
inputs = {key: val.to(model.device) for key, val in inputs.items()} # Ensure inputs are on the same device as model
outputs = model(**inputs)
cls_embeddings = outputs.last_hidden_state[:, 0, :].cpu().numpy() # CPU로 결과 이동
embeddings.extend(cls_embeddings)
return np.array(embeddings)
# 텍스트 임베딩 추출
embeddings = get_embeddings(texts, tokenizer, model)- K-means 모델을 사용하여 파인 튜닝
# K-평균 클러스터링 수행
num_clusters = 7 # 클러스터 수 설정
kmeans = KMeans(n_clusters=num_clusters, random_state=0).fit(embeddings)
# 각 텍스트에 대한 클러스터 할당
cluster_labels = kmeans.labels_
# 클러스터링 모델 저장
with open('kmeans_model.pkl', 'wb') as f:
pickle.dump(kmeans, f)모델 학습 결과
- PCA를 사용하여 클러스터링 결과 시각화 및 중심 문장 추출
# 클러스터링 결과 시각화 (PCA 사용)
pca = PCA(n_components=2)
reduced_embeddings = pca.fit_transform(embeddings)
plt.scatter(reduced_embeddings[:, 0], reduced_embeddings[:, 1], c=kmeans.labels_, cmap='viridis')
plt.title('Text Clustering with KMeans')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 클러스터 중심 및 주변 텍스트 파악
def get_cluster_centers_texts(embeddings, labels, texts, num_clusters, num_neighbors=10):
cluster_centers_texts = {}
for i in range(num_clusters):
cluster_indices = np.where(labels == i)[0]
cluster_embeddings = embeddings[cluster_indices]
cluster_texts = [texts[idx] for idx in cluster_indices]
center_idx, _ = pairwise_distances_argmin_min(kmeans.cluster_centers_[i].reshape(1, -1), cluster_embeddings)
center_idx = center_idx[0]
# 중심 문장과 가장 가까운 10개의 문장 찾기
distances = np.linalg.norm(cluster_embeddings - cluster_embeddings[center_idx], axis=1)
neighbor_indices = np.argsort(distances)[:num_neighbors + 1] # 중심 문장을 포함한 가장 가까운 문장 인덱스
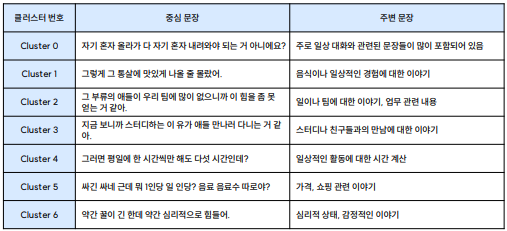
cluster_centers_texts[i] = {
'center_text': cluster_texts[center_idx],
'neighbor_texts': [cluster_texts[idx] for idx in neighbor_indices if idx != center_idx]
}
return cluster_centers_texts
# 중심 및 주변 텍스트 파악
cluster_centers_texts = get_cluster_centers_texts(embeddings, cluster_labels, texts, num_clusters)
# 클러스터 내용 출력
for cluster, texts in cluster_centers_texts.items():
print(f"Cluster {cluster} 중심 텍스트: {texts['center_text']}\n")
print(f"Cluster {cluster} 주변 텍스트:")
for neighbor_text in texts['neighbor_texts']:
print(f"- {neighbor_text}")
print("\n")
728x90
반응형