목차
728x90
반응형
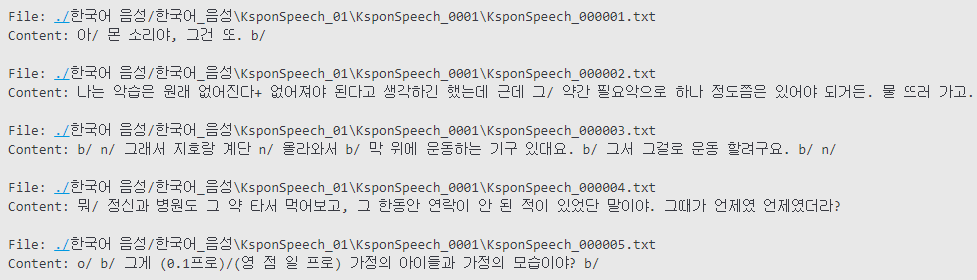
데이터 구조 탐색
- 음성 데이터를 텍스트로 옮겨서 전처리 진행
- 변환 과정에서 발생한 문제
- 문장 구분을 위한 '/', 'n/'과 같은 특수 문자 포함
- 내용을 설명해주는 부가적인 텍스트 삽입
- 표준어가 아닌 구어체
- 변환 과정에서 발생한 문제
1. 텍스트 정규화
1-1. 정규 표현식
- 정규 표현식을 사용하여 불필요한 문자 제거
- '/', 'n/'과 같이 특수하게 문장을 구분하는 형식을 공백으로 대체
- 영문자, 한글, 숫자, 공백, 일부 문자부호만 남기고 나머지 형식을 공백으로 대체
# 정규표현식을 이용해 불필요한 문자 제거
def remove_text(texts_dict):
processed_texts = {}
for file_path, text in texts_dict.items():
# 소문자 알파벳 뒤에 /와 공백이 오는 형식 제거
text = re.sub(r'[a-z]/\s', ' ', text)
# 불필요한 문자 제거: 영문자, 숫자, 공백, 한글, 일부 문장부호만 남김
text = re.sub(r'[^\w\s?.!가-힣]', ' ', text)
processed_texts[file_path] = text
return processed_texts1-2. PyKoSpacing
- PyKoSpacing을 사용하여 띄어쓰기 교정
- 불필요한 문제 삭제로 생긴 비정상적인 공백 형식 교정
# PyKoSpacing을 사용하여 띄어쓰기 교정
from pykospacing import Spacing
def correct_spacing(texts_dict):
spacing = Spacing()
corrected_texts = {}
for file_path, text in texts_dict.items():
# 띄어쓰기 교정 적용
corrected_text = spacing(text)
corrected_texts[file_path] = corrected_text
return corrected_texts1-3. ET5 Text2Text
- ET5 Text2Text Generation Transformer model을 사용하여 맞춤법 교정
- 한국어 구어체(대화체) 전용 맞춤법 교정 모델
# ET5 Text2Text Generation Transformer model을 사용하여 맞춤법 교정
# 모델과 토크나이저 로드
model = T5ForConditionalGeneration.from_pretrained("j5ng/et5-typos-corrector")
tokenizer = T5Tokenizer.from_pretrained("j5ng/et5-typos-corrector")
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = model.to(device)
# 각 텍스트 항목에 대한 맞춤법 검사 및 교정
for key, text in data.items():
input_text = "맞춤법을 고쳐주세요: " + text
input_encoding = tokenizer(input_text, return_tensors="pt")
input_ids = input_encoding.input_ids.to(device)
attention_mask = input_encoding.attention_mask.to(device)
output_encoding = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_length=128,
num_beams=5,
early_stopping=True
)
output_text = tokenizer.decode(output_encoding[0], skip_special_tokens=True)
correctedspell_texts[key] = output_text
print(f'Corrected: {output_text}\n')728x90
반응형
'Project > 한국어 대화 분류 및 요약' 카테고리의 다른 글
| [Project] 한국어 대화 분류 및 요약 - 성능 및 결론 (0) | 2024.07.08 |
|---|---|
| [Project] 한국어 대화 분류 및 요약 - 모델 학습 (0) | 2024.06.09 |
| [Project] 한국어 대화 분류 및 요약 - 데이터 전처리 2 (0) | 2024.06.09 |
| [Project] 한국어 대화 분류 및 요약 - 데이터 수집 (0) | 2024.05.02 |
| [Project] 한국어 대화 분류 및 요약 - 프로젝트 계획 (0) | 2024.05.01 |