목차
728x90
반응형
1. Data Collecting
- 서울시 5대 범죄, 날씨, 지역, 인구 데이터 수집
- 데이터 수집 기관
- 범죄 데이터 : 서울특별시 경찰청
- 날씨 데이터 : 기상청
- 인구 데이터 : 서울 열린 데이터 광장
- 지역 데이터 : 서울 열린 데이터 광장, 토지 대장 등
- 모든 데이터는 2020년1월 부터 2022년12월 까지 3년치 데이터를 수집
2. PreProcessing
2-1. 범죄 데이터
- 1월부터 12월까지 월별로 구성된 범죄 데이터를 이용해 feature engineering 진행
- filter 함수를 이용해 연도별 범죄건수 총합을 구함
- (월별 범죄건수/연도별 범죄총합) * 100 -> 월별 범죄율
- (연도별 범죄총합/ 총 범죄건수) * 100 -> 연도별 범죄율
# filter 함수
data['20년_범죄총합'] = data.filter(like='20년').sum(axis=1)
# 월별 범죄건수, 범죄율
for month in range(1, 13):
data[f'20년{month}월_범죄건수'] = (data[f'20년{month}월_살인'] + data[f'20년{month}월_강도'] + data[f'20년{month}월_강간/강제추행'] + data[f'20년{month}월_절도'] + data[f'20년{month}월_폭력']) # 범죄건수
data[f'20년{month}월_범죄율'] = (data[f'20년{month}월_범죄건수'] / data[f'20년_범죄총합']) * 100 # 범죄율
# 총 범죄건수, 연도별 범죄율
data['총범죄건수'] = data['20년_범죄총합'] + data['21년_범죄총합'] + data['22년_범죄총합']
data['20년_범죄율'] = (data['20년_범죄총합'] / data['총범죄건수']) * 100
# 실행코드 일부 발췌2-2. 날씨 데이터
- 강수, 기온, 풍속, 습도 등 데이터를 불러와 필요한 column만 추출 후 하나의 파일로 concat
- 생성한 파일의 결측치 삭제 후 저장
# 데이터에서 필요한 칼럼만 가져오기
new_columns = ['일시', '강수량(mm)', '일최다강수량(mm)']
rain = rain[new_columns]
t_new_columns = ['평균기온(℃)', '평균최고기온(℃)', '최고기온(℃)', '평균최저기온(℃)', '최저기온(℃)']
temp = temp[t_new_columns]
w_new_columns = ['평균풍속(m/s)', '최대풍속(m/s)', '최대순간풍속(m/s)']
wind = wind[w_new_columns]
h_new_columns = ['평균습도(%rh)', '최저습도(%rh)']
humidity = humidity[h_new_columns]
# 행 기준으로 데이터프레임 합치기
df = pd.concat([rain, temp, wind, humidity], axis=1)
# 결측치 제거
df = df.dropna()
# 데이터 저장
df.to_csv('날씨데이터총합.csv', encoding='cp949', index=False)
# 실행코드 일부 발췌2-3. 인구 데이터
- 필요없는 index, column 삭제
- column을 원하는 이름으로 rename
# index 삭제
pop = pop.drop(0)
# column rename
pop.rename(columns={'동별(2)':'자치구', '2020':'2020_세대수', '2020.1':'2020_한국인'. '2020.2':'2020_등록외국인'})
# 실행코드 일부 발췌2-4. 지역 데이터
- 토지 대장에서 수집한 건축물 높이와 건폐율 관련 데이터를 지역별로 구분하여 사용하려 했지만 결측치가 너무 많아 사용하지 못 했음.
3. Visualization & Insight
3-1. 시각화를 통한 인사이트 파악
- 연도별 범죄 건수 데이터를 선 그래프로 시각화하여 범죄가 가장 많이 일어나는 지역 확인
# 2020년 범죄 총합 시각화
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Malgun Gothic'
# 그래프의 크기를 설정합니다.
plt.figure(figsize=(15, 6))
# 자치구를 x축으로, 20년 범죄총합을 y축으로 하는 선 그래프를 그립니다.
plt.plot(df['자치구'], df['20년_범죄총합'], marker='o', linestyle='-')
# x축 레이블 회전
plt.xticks(rotation=45)
# 그래프의 타이틀과 축 레이블을 추가합니다.
plt.title('자치구별 20년 범죄총합', fontsize=16)
plt.xlabel('자치구', fontsize=14)
plt.ylabel('20년 범죄총합', fontsize=14)
plt. savefig("20년도 자치구별 범죄총합 시각화.png")
# 그래프를 표시합니다.
plt.show()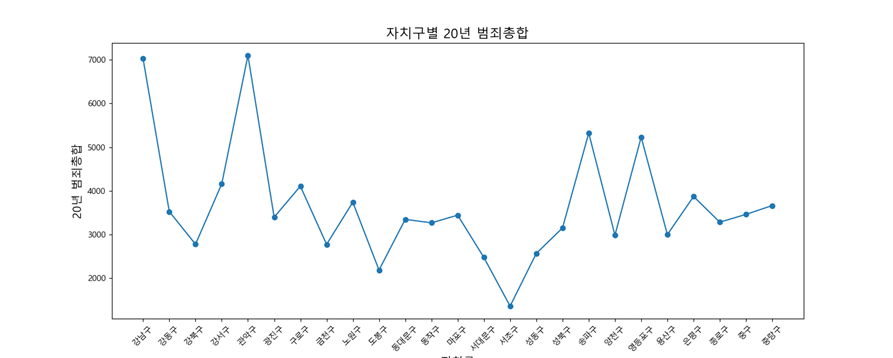

- 전체적으로 강남구, 송파구, 영등포구에서 범죄 수가 가장 높게 나타남을 확인
- 2020년 이후 관악구의 범죄건수가 많이 떨어진 것을 확인
- 같은 방법을 통해 지역별 범죄건수 변화 확인
- 대체로 2021년에 범죄가 많이 줄어들었음
- 노원구, 동대문구, 관악구는 범죄 수가 감소하고 있음을 확인
- 강동구, 도봉구, 강서구는 범죄 수가 증가하고 있음을 확인
3-2. 상관관계 분석을 통한 인사이트 파악
- Scikit-learn의 linear model을 이용해 범죄율과 인구에 대한 상관관계 확인
- 나이대별 남여에 대해 범죄와의 상관관계 확인
# 선형 관계의 대한 절편, 계수, 점수
linear_regression.fit(X = pd.DataFrame(df['2020_40대_남자']), y = df['총범죄건수'])
prediction = linear_regression.predict(X = pd.DataFrame(df['2020_40대_남자']))
print('절편', linear_regression.intercept_)
print('계수', linear_regression.coef_)
print('점수', linear_regression.score(X = pd.DataFrame(df['2020_40대_남자']), y = df['총범죄건수']))
print('-----------------------------')
linear_regression.fit(X = pd.DataFrame(df['2020_40대_여자']), y = df['총범죄건수'])
prediction = linear_regression.predict(X = pd.DataFrame(df['2020_40대_여자']))
print('절편', linear_regression.intercept_)
print('계수', linear_regression.coef_)
print('점수', linear_regression.score(X = pd.DataFrame(df['2020_40대_여자']), y = df['총범죄건수']))
# 범죄와 인구 데이터에 대해 scatter로 시각화하여 선형 관계 확인
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.figure(figsize=(15, 5))
plt.subplots_adjust(left=0.125, bottom=0.1, right=0.9, top=0.9, wspace=0.2, hspace=0.4)
plt.subplot(121)
plt.scatter(df['2020_40대_남자'], df['총범죄건수'], color='b')
plt.title('2020년 40대 남자')
plt.subplot(122)
plt.scatter(df['2020_40대_여자'], df['총범죄건수'], color='r')
plt.title('2020년 40대 여자')
plt. savefig("2020년 40대 1인가구_남여 상관관계.png")
# 실행 코드 일부 발췌
- 인구와 관련된 각종 칼럼들의 상관관계를 분석해본 결과
- 30대 남자, 40대 여자가 가장 높은 상관관계를 가짐
- 등록 외국인 수, 고령 인구는 아주 낮은 상관관계를 가짐
- 각종 날씨 데이터는 터무니 없는 분석 점수를 가짐
- 날씨 데이터의 경우 서울시의 각 구별 날씨가 아닌 서울시 전체의 날씨를 나타내고 있음
- 이에 각 구별 범죄율를 예측하는데 사용하기엔 한계가 있다고 판단되어 분석 데이터에서 제외
728x90
반응형
'Project > 서울시 범죄 발생률 예측 서비스' 카테고리의 다른 글
| [Project] 서울시 범죄 발생률 예측 서비스 - DB (2) | 2024.08.06 |
|---|---|
| [Project] 서울시 범죄 발생률 예측 서비스 - Server (0) | 2024.06.09 |
| [Project] 서울시 범죄 발생률 예측 서비스 - Front 1 (0) | 2024.06.09 |
| [Project] 서울시 범죄 발생률 예측 서비스 - 프로젝트 계획 (0) | 2024.06.09 |